Kotlin avoids entire categories of Java defects
This article looks at many categories of Java bugs that Kotlin prevents in addition to null safety.
My first article provided a brief introduction to Kotlin and showed a surprising impact on productivity. The positive feedback and popularity of that article motivated me to write this second part (thank you).
Motivation
Organizations spend considerable resources dealing with software defects. A reduction in defect rates reduces the need to allocate extra resources for fixing them and directly affects the bottom line.
The cost of defects can be much higher in later phases of the software development life-cycle. This is due to extra steps such as investigation by technical support, creating custom workarounds, and the difficulty in hunting down defects that manifest themselves through side effects. More importantly, defects can cause a loss of business and affect credibility.
As developers, we encounter defects on a regular basis since feature work is an iterative process with new defects introduced and fixed along the way. A reduction in defect rates improves team velocity and the rate of additional technical debt is reduced as well. The test automation effort is also reduced since we don’t need to test scenarios that are prevented at the language level.
Note that whatever bottlenecks we experience while fixing defects (eg. slow environment setup) are avoided if the defect didn’t exist in the first place.
It’s important to realize the difference in value in fixing a defect in one class versus preventing an entire category of defects from occurring in any class. Preventing defects also has a compounding effect since defects typically manifest themselves through side effects which lead to even more defects. Preventing defects reduces the amount of band-aid style hot-fixes which are known to cause spaghetti code. Future capacity is also improved and cognitive effort is reduced since we won’t need to spend time fixing or thinking about these categories of defects.
Equality Defect Categories
A common source of defects in Java is caused by accidentally checking referential equality instead of true value equality. The examples below show how these types of defects can be introduced even by experienced developers.
The confusion stems from “==” having a dual purpose. Primitives must be compared using “==” and unfortunately you can also use “==” to check object referential equality. The line is further blurred since “==” works as expected for certain types of objects such as singletons, enums, Class instances, etc. so these defects can be sneaky.
Using “==” in Kotlin checks true value equality so it avoids these common categories of defects:
- Changing the method return type from primitive to wrapper type still compiles but can break existing equality checks:
// Java// getAge() returned an int so this check was correct but
// was later changed to return Integer
if (brother.getAge() == sister.getAge()) // potential twins...similarly for all 8 primitive types
- Refactoring by inlining code can break equality checks when autoboxing / unboxing is involved since it looks like we’re dealing with primitive types:
// Javaint employeeAge = employee.getAge();
int supervisorAge = supervisor.getAge();
if (employeeAge == supervisorAge)// Refactor the above 3 lines and replace with this broken version:
if (employee.getAge() == supervisor.getAge())...similarly for all 8 primitive types
- Object caching further complicates things since referential equality can work correctly during testing and fail with customer data:
// JavaInteger first = 100;
Integer second = 100;// Condition passes since these values use the Integer cache
if (first == second)...
Integer third = 200;
Integer fourth = 200;// Oops, condition fails since 200 is out of range of Integer cache
if (third == fourth)...factory pattern can cause similar caching problems with any class
- Checking referential equality when we shouldn’t. This can occur if we’re not careful. It can also be caused by more complex scenarios where it used to work correctly (eg. break checks by no longer interning strings):
// Javaif (firstName == lastName)
abortOperation("First name must be different than last name);
If you purposely want to check for referential equality, Kotlin has triple equals for that so it’s never accidental. A nice addition is that Kotlin eliminates the null check clutter when checking against potential null values due to its stronger type system (details in the “Null Defect Categories” section below).
Data Class Defect Categories
Good design principles suggest packaging related data together. For example, a Person class stores various properties of a person:
// Kotlindata class Person(var name: String, val dateOfBirth: LocalDate)
That’s right, a single line of Kotlin fully defines the Person class. The data keyword generates getters, setters, toString, equals, hashCode, copy, and other functions to enable additional useful language features. The equals and hashCode methods are important as we usually work with collections.
Defining an equivalent Person class in Java requires much more than 1 line:
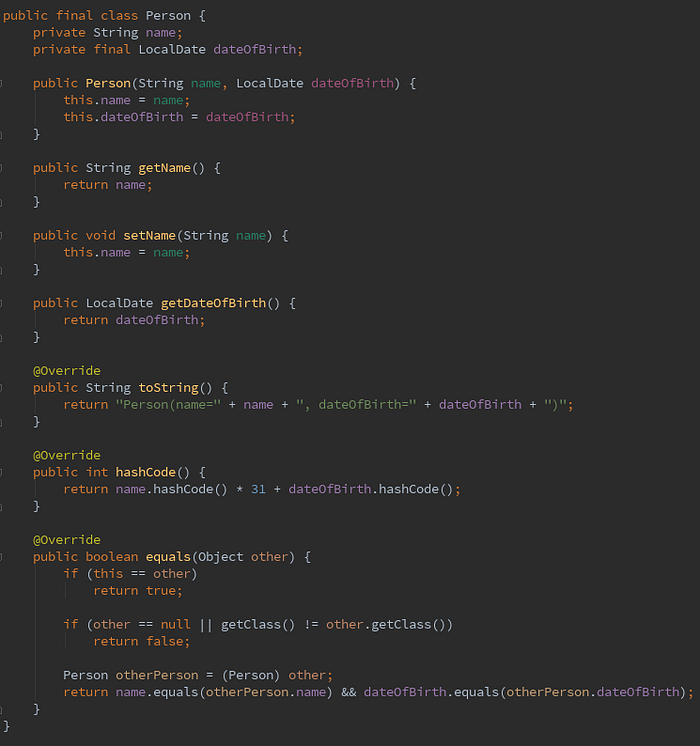
Oops, I lied. The Java version is not quite equivalent since it’s missing an easy way to copy it (eg. clone or copy constructor). I also had to strip out all the nullability annotations and trivialize the Person class with only 2 properties to fit it in the screenshot but data classes typically contain at least a handful of properties. The size difference increases when you add JavaDocs on multiple methods versus the single Kotlin doc for the data class.
Kotlin data classes are much easier to understand and automate most of the work which avoids these categories of defects:
- Checking referential equality in equals instead of true value equality for some of the properties.
- Missing Override annotation on equals method and incorrect method signature (defining the parameter as Person instead of Object).
- Non-final class with instanceof check in equals doesn’t account for subclasses. Eg. person.equals(manager) must provide the same result as manager.equals(person).
- Logic mistakes are common when implementing hashCode especially if some of the properties can be null.
- Implementing equals without implementing hashCode (or vice versa).
- Inconsistent equals & hashCode implementation. Two instances that are equal must always produce the same hashCode.
- Poor hashCode implementation can cause many collisions and introduce scalability issues.
- Missing nullability annotations or forgetting to guard against null parameters
- Another property is added in the future and equals / hashCode / toString methods are forgotten or not updated correctly.
Switch Defect Categories

Kotlin replaced the switch statement with a more powerful “when”:
// Kotlinval priorityColor = when (priority) {
LOW -> Color.GREEN
MEDIUM, HIGH -> Color.YELLOW
CRITICAL -> Color.RED
}
Whenever we use “when” as an expression (such as in the above example), the compiler ensures that all scenarios are covered and prevents the following defect categories:
- Forgetting a case (eg. missing an enum value).
- Adding a new enum value and forgetting to update all the switch statements (especially if the enum is used by different teams).
- Missing break is a common defect that causes accidental fall through:
// Javaswitch (priority) {
case LOW:
priorityColor = Color.GREEN; // Oops, forgot break
case MEDIUM:
...
}
We can also use “when” as a replacement for if-else chains which makes them much easier to follow and less error prone:
// Kotlinfun isHappy(person: Person): Boolean {
return when {
person.isPresident -> false
person.isSmart -> person.age < 10
else -> person.salary > 100000
}
}
Assignment Defect Categories
Unlike Java, an assignment is a statement in Kotlin (which does not evaluate to a value) so it cannot be used in a condition. This prevents the following defect categories:
- Accidental boolean assignment in condition:
// Javaboolean isEmployed = loadEmploymentStatus(person);// Incorrect check due to assignment
if (isEmployed = person.isMarried())
// Employed and married or unemployed and single...
if (isEmployed) // this variable was accidentally modified
- More complex conditions can accidentally assign variables of any type:
// Java// Attempt to determine twins based on age
boolean singleSetOfTwins = ((age1 = age2) != (age3 = age4))
Override Defect Categories
Kotlin made “override” a mandatory keyword when overriding methods which prevents the following categories of defects:
- Accidentally override superclass method by adding a method to a subclass.
- Adding a method to a base class not realizing that it won’t be executed because a subclass has a method with the same signature.
- Missing the override annotation and changing a subclass method signature not realizing that it will no longer override a superclass method.
- Changing the method signature in a base class without realizing that a subclass overrides it which is missing the override annotation.
- Missing the override annotation and using incorrect spelling or capitalization (eg. hashcode instead of hashCode) so it’s not overriding the superclass method.
Null Defect Categories
Null is by far the most common cause of defects in Java and masquerades itself in many forms.
I call it my billion-dollar mistake. It was the invention of the null reference in 1965. (source)
- A common practice is to validate parameters at entry points and pass them to helper functions with an implied contract that they’ve already been verified. It’s also a best practice to replace a large function with a function that calls a bunch of smaller private ones. This allows each function to be easily understood and verified so the concept of entry points is very common. These implicit contracts are accidentally violated when adding a feature or fixing a defect. The entry points are often modified or variables are re-assigned by calling other functions which might return null. In the simplest case, this can cause a null pointer exception. Unfortunately, the unexpected null can also manifest itself through strange side effects.
- Autoboxing / unboxing. Here’s a sneaky null pointer exception that’s waiting to happen when the user isn’t in the map:
// Javapublic boolean makesOverAMillionDollars(String name) {
Map<String, Long> salaries = getSalaries();
long salary = salaries.get(name);// Unbox null to long causes NPE
return salary > 1000000;
}
- A null Boolean is often interpreted as false.
// Java// This check is accidentally circumvented by a null value
if (Boolean.TRUE.equals(isSuspiciousAction)) reportToAuthorities();
- A null String is often interpreted as empty (eg. the user didn’t enter any value) when we may not have extracted the value correctly.
- A null Integer is sometimes interpreted as 0 which causes surprises (eg. database ResultSet).
- Data can accidentally be cleared by null values. Even if we write code to populate a variable with a non-null value before storing it, these instructions are sometimes preempted by exceptions.
- Null is the cause of other types of exceptions as well. It’s a best practice to throw an IllegalArgumentException when parameters don’t conform to the contract (eg. passing a null identifier when creating a BankAccount).
Incorrect use of null is the cause of roughly 30% of all defects in Java. An investigation involving 1000 Java applications found that 97% of errors were caused by only 10 different Exception classes with NullPointerException being the most popular. The linked study gives us a rough idea of the minimum benefit if we eliminate it because accidental null causes multiple types of problems in addition to NullPointerException as shown above.
Kotlin prevents these categories of defects with its stronger type system that has nullability built-in. You are forced to make a decision about what should happen whenever a variable might be null. Unlike other languages, this has zero memory or runtime overhead which avoids scalability concerns.
- Nullable variables are allowed to be set to null:
// Kotlin// Nullable types are declared with "?"
var spouseName: String? = null // allowed
- Variables that are not declared as nullable cannot become null:
// Kotlinvar name: String = "Dan"
name = null // Compiler error, name is not nullablevar spouseName: String? = getSpouseName() // null if not married
name = spouseName // Compiler error, spouseName might be null
- The compiler prevents calling methods on variables that might be null:
// Kotlinval spouse: Person? = getSpouseOf("Bob") // null if not married
spouse.speak() // Compiler error, spouse might be null
- You can use a nullable variable directly if the compiler can prove that it’s never null:
// Kotlinif (spouse != null) {
spouse.speak() // Allowed since it will never be null here
}
- Kotlin has several shortcuts which make it easier to work with nullable types. This reduces null check clutter so we can focus on business logic:
// Kotlin// Safe call operator "?." evaluates to null if the variable
// is null without attempting to call a method on it
spouse?.speak()// Elvis operator "?:" specifies default when left side is null
val spouseSalary = spouse?.salary ?: 0// If spouse is null then "spouse?.salary" evaluates to null so
// default to 0 for the spouse salary
This is different from tools like FindBugs which try to spot null errors because Kotlin takes the opposite approach. Rather than trying to spot null errors, the compiler only passes if it can prove that a variable will never be null whenever it’s used as a non-null value.
Summary
Kotlin avoids many of the popular defect categories that occur in Java. Although I had high expectations, I was shocked to find so many improvements everywhere I looked. To my continued surprise, I kept discovering additional categories of defects that Kotlin prevents. The language design really starts to shine when subjected to this level of scrutiny and we’re just getting started.
Having Kotlin code which compiles means much more than compiling Java code because this tells us that we didn’t run into the above categories of defects (or combinations of the above).
Most developers strive to achieve some level of perfectionism. This causes some amount of subconscious worry due to the combinatorial explosion in the number of possible states. The many language-level guarantees that Kotlin has a large impact on how safe we feel about our code. This cuts down on the subconscious concerns so it’s easy to see why Kotlin is ranked as the second most loved language (after the systems language Rust) according to a recent Stack Overflow survey. Although feelings can be subjective, this is a real logical reason why developers enjoy working with Kotlin besides the many other benefits such as improved productivity.
I must admit, switching from Java to Kotlin for my back-end projects feels amazing. The language guarantees that the code is much more robust and boosts your confidence. This allows you to focus on the data model and business logic which also improves productivity.
Before discussing the impact on defect rates, we need to first talk about the majority of defect categories that Kotlin prevents but we’re not even close.
Follow and subscribe to be notified of my next article.

