Fueled Reactive apps with Asynchronous Flow — Part 3 — Data layer Implementation

(This article was featured at Android #418 Weekly)
The most exciting moment for a software engineer surely is when enjoys coding and gets stuff done. However, for the pragmatic developer, implementation details should be as important as the process to get things done, because the difference is on the details, isn’t?
Throughout Part 3, I will elaborate throughout the Implementations details from the Data layer. Firstly I will start with “Data Sources Design: Network & DB”. I will go deep inside “Repository Design Step 1: RxJava approach”, what I call the naive approach. Finally, I will cover “Repository Design Step 2: suspend approach”, a more natural way to writing Coroutines.
But first things first, to get all started we need to add a couple of dependencies to make Kotlin Coroutines and Flow happy:
Any version up from 1.3 makes Coroutines stable on Kotlin.
For the first step of the migration, my approach was to go deep inside, concretely from the Data Layer. Where the data is coming from the Internet and is transformed into Database (DB) models to be used where needed.
Data Sources Design: Network & DB
This transformation starts from an old code base mostly based on RxJava + Java towards a more modern Kotlin + Coroutines equivalent.

For further details about this and other decisions on the Migration strategy, please read Part 1:
Network data source
The NetworkDataSource implementation will be the first candidate to migrate, but let’s see what we have inside:
For me a DataSource should be a @Singleton, in this way, we can avoid initialising heavy artefacts many times and using them on demand (I assumed we will use network requests more than once). From the set of dependencies injected we can see:
- A
TwitterApito make API requests built upon Retrofit composed with an OkHttp client inside. - a
ConnectionHandlerto check any connection availability. - a
RequestIOHandlerto transform network responses to their network data source model. - and finally a
TaskThreading.
Let’s stop here to analyse a little bit more what is within TaskThreading:
My personal preference is using composition over inheritance, this usually makes the code more scalable, extendable and testable but again, this is my preference. By having final instances created from the static methods and getters, we can easily mock each correspondent Scheduler from getter public methods for unit tests. Of course, there are multiple ways to make this, we could inject those schedulers instances directly through the constructor.
Now it’s the turn for the main method to start processing a request with the query: search(). Let’s have a look at the legacy but declarative code I had at the time using RxJava with Java code:
This method retrieves a list of Tweets from the Twitter API by subscribeOn() on the IO thread pool. Of course, passing a valid token in combination with the query whose user is looking for. By using observeOn() on the computation thread pool, to perform any transformation operations until we retrieve those tweets. We finally would wrap them into a Single (because we don’t expect more interactions with the network), in order to achieve this, flatMapSingle() transforms Maybe into a Single.
Thinking on a Coroutines version of the same method, ideally, we would just have to write the following imperative code:
The code looks simpler, we return a bad or a wrong response wrapped with Either. Either (from the Arrow Core library) is returned with the right result or the wrong (left) result. Notice this code doesn’t show further examples of error handling (for the Twitter API) in combination with Either to simplify this snippet.
For learning purposes, starting to play with Flow, the first naive approach that came to my mind is this:
search() is using the flow {} builder that runs into the context provided for the specific Flow and its Coroutine. This context can be switched by means of flowOn() like the IO Dispatcher defines.
Now TaskThreadingImpl is extended with a combination of Dispatchers plus the previously added Schedulers, ioDispatcher() is defined within:
Moreover, asObservable() converts the given flow to a cold Observable. Here is where the magic of kotlinx-coroutines-rx2 is coming from:
This library is extremely helpful and convenient in order to transform towards both directions:
RxJava ← → Coroutines
To migrate amongst layers without breaking changes, it is definitely a must-do.
We would simply add this to make it work:
However, I know the previous snippet of code isn’t the best. There is an important drawback:
- returns an
Observable- This is not ideal since we only need aSingle. The stream closes immediately after execution.
We’ll get back to this point later to introduce a proper solution.
DB data source
Now looking at the DB data source, Room has a convenient interface where a selected set of tweetsIds can be extracted from the DB query with different outputs such as Observable, Single, suspend functions or Flow.
For a DB would make more sense than for a network request to return an Observable:
- situations like a network Poll: refreshing in the background our DB would make sure to refresh the data rendered into the UI . Therefore any new changes added into the DB will be refreshed on due time by means of the open stream.
Next, I followed my instincts and I started what I call “the naive approach”, by using RxJava first.
Repository Design Step 1: RxJava approach
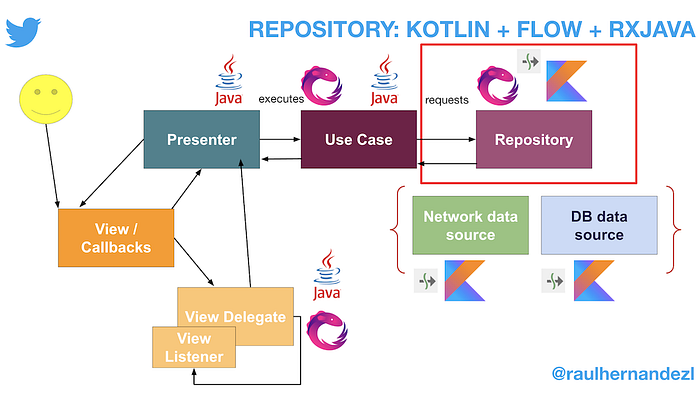
Let’s have a look at the TweetsRepositoryImpl anatomy:
The repository, for me, must be a @Singleton too. It contains very heavy objects that surely will be reused a number of times. It is composed by the NetworkDataSource interface, the different DB DAO interfaces (each one is equivalent to a table in the DB), the mappers to transform data source data into the data expected for the business logic layer, without forgetting the TaskThreading to use the right Dispatcher when necessary.
Reminder to our future-selves, this should be what the NetworkDataSourceImpl should return: Single. In case we still need to return a RxJava object for backwards compatibility:
This is achieved by using the kotlinx-coroutines-rx2 library again.
However, I wanted to experiment a few more things with the RxJava approach, this hasn’t finished yet!
Here I am getting the Observable from the NetworkDataSource::search, mapping from an Either to an entity my DB DAOs support: tweetsToAdd. Now I will only receive one iteration of the doOnNext, but the workflow is like follows:
- Make sure to delete (the previously saved in DB) tweets belonging to the same query to avoid duplications
- insert new tweets (TweetDao)
- insert query (QueryDao)
- insert association across Tweets and Query (TweetQueryJoinDao)
The first flatMap retrieves all tweetIds for each query coming from the doOnNext, the second flatMap uses them to retrieve all Tweets for each tweet id returning an Observable from that point.
Let’s start migrating RxJava to its Kotlin Flow equivalent:
Looking at the code above first, we need to include a few annotations: FlowPreview, ExperimentalCoroutinesApi and InternalCoroutinesApi. Note that at the time I prepared this presentation, certain Flow operators were still experimental and these annotations were needed.
Kotlin Flow looks very similar. Simply changing flatMap() to become flatMapConcat() and using onEach() instead of onNext(). Internally retrieveAllTweetsForTweetsIdsFlow is returning a Flow now, due to our return@flatMapConcat is expecting to return a Flow. Concluding this block of code, finally, we still need to return an Observable towards the UseCase by means of asObservable().
It is important to have in mind that we need to use flowOn() to switch contexts only if necessary. For instance, if we declare our preferred Dispatcher on the upper layer (the Repo), we wouldn’t need to change it downstream (data sources), because the coroutine context would be the same.
Repository Design Step 2: suspend approach
To really have an idiomatic and correct Coroutines approach, we need to use suspend functions as much as possible, and this means to get rid of our RxJava approach to writing easier to read Coroutines code, using only streams when is really needed.
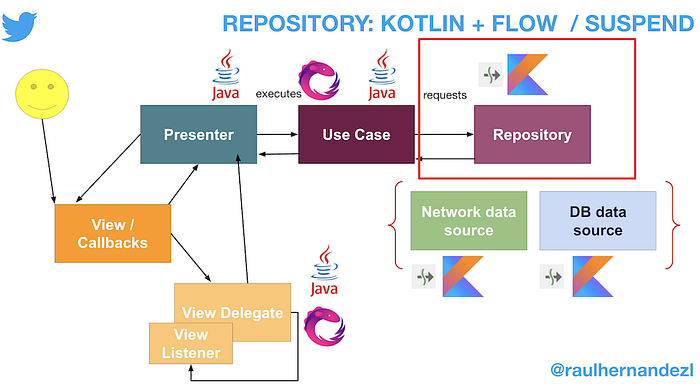
The first step here is, transform everything we can into suspend functions.
Once the TweetDao returns a List by means of a suspend function we can continue.
Within our suspend function we can write with an imperative style.
But I still need for my repo an open stream. Thus, I need to use an Observable here, or better said, a Flow transformed into an Observable:
TweetsRepositoryImpl returns an Observable of Tweets after invoking asObservable(). This will transform the result from the flow builder block. That block calls emit() with the previous DB data and later emit() again with the fresh data coming from the network, once the DB was updated by calling retrieveAllTweetsForTweetsIds method from the TweetDao.
Other possible usages:
- operator
emitAll: emits all values from the stream, for example by using the previously mentioned Poll:
fun getSearchTweets(query: String): Flow<List<Tweet>> {
// ...
emitAll(tweetsDBDataSource
.retrieveAllTweetsForTweetsIdsFlow(tweetIds))
}In that case, we would substitute emit() for emitAll(), we would need to return a Flow (an open stream of values) at the end.
Other not possible usages:
- we cannot use inside a
suspendfunction with a method returning aFlow:
suspend fun getSearchTweets(query: String): List<Tweet> {
// ...
return tweetsDBDataSource
.retrieveAllTweetsForTweetsIdsFlow(tweetIds)
}A suspend function is expecting to return an Object or any of its variants like we can read at Part 2:
Until here we have learned how to come from a naive RxJava to a more idiomatic Coroutines approach, using the right tools for the right job in Kotlin, with both suspend functions and Kotlin Flow.
This is all for Part 3, so far we have reviewed the deepest layer of the Implementation sub-section:
- Data layer Implementation
If you liked this article, clap and share it, please!
Cheers!
Raul Hernandez Lopez
I want to give a special thanks to Jorge Castillo for reviewing this article and to make it more readable. He knows a ton about functional programming, especially about the Arrow library (contributor and maintainer), follow him!
(Update) The newest article talking about “Synchronous communication with the UI using StateFlow" (aka how to get rid of the Callbacks):
To follow up, other Implementation sub-sections will be:
- “Use Case layer Implementation”. How-to.
- “View Delegate Implementation”. How-to.
And finally:
- “Lessons learned & Next steps”. The end chapter with some reflections and personal opinions as well as closing comparative notes.

