Cloud Face Recognition for Mobile Applications: Evaluation
Results from Implementing 5 Best Face Recognition APIs
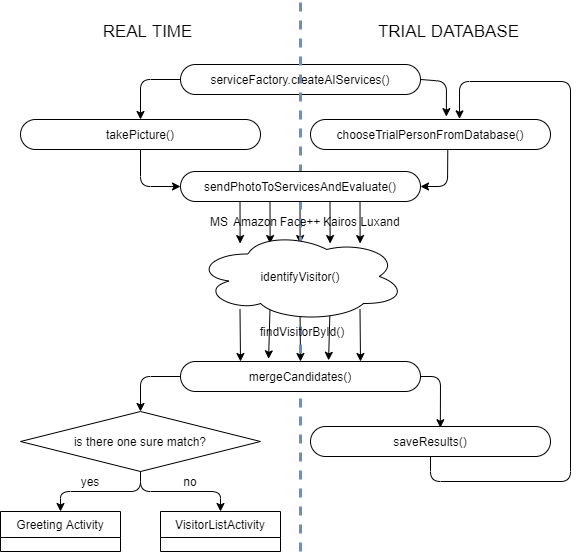
In the previous chapters of this series we’ve discussed several cloud face recognition services and designed a prototype app. Now it is time to test the chosen providers and evaluate their performance.
If you are interested in other parts of the series, check these out:
Part 1: Overview of some popular face recognition services
Part 2: Implementation example in Android
Part 3: Results and performance of chosen face recognition providers

After we’ve been through design and implementation, it‘s time to harvest the results. For this purpose my prototype has two modes: demo and test mode.
Demo mode
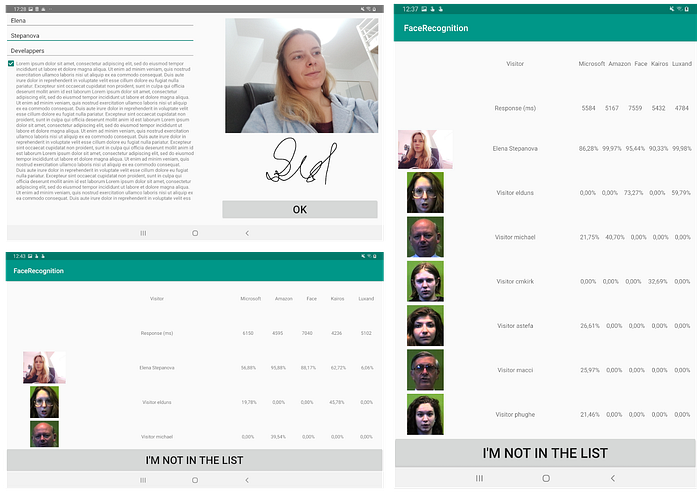
The demo mode has functionality of a visitor surveillance system and is used to show how different providers react to slight changes in the appearance.
First, I registered myself within the AI service and the local database. Then I took a series of pictures, which a friend of mine called “I killed my husband and went for a run”. The recognition results were as follows.

In most cases cloud services were rather confident about the fact that me wearing glasses or long hair is still the same me. As expected, some changes in appearance have led to lower confidence levels, however, they were still negligible. Only in case of Luxand, I could probably get away with the murder just wearing a hairdo and glasses.
Test mode
Unlike demo mode, the test mode is used to collect and compare results of various cloud service providers applied to a test database.
In face recognition the performance of machine learning algorithms is usually measured by calculating useful metrics, such as
TP - true positives (correctly recognised candidates)
TN - true negatives (correctly rejected candidates)
FP - false positives (candidates that should not have been accepted)
FN - false negatives (rejected candidates that should have been accepted)
Then these values are used to calculate true negative rate, which measures the proportion of actual negatives that are correctly identified as such.
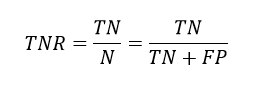
We can also estimate precision, recall (sensitivity, TPR) and accuracy of the face recognition services.
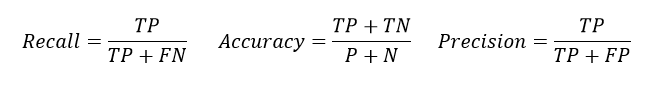
In addition to accuracy, which can give misleading results for imbalanced data sets, it is suggested to calculate balanced accuracy, which uses the TPR and TNR instead of absolute values.
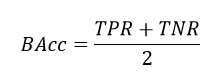
The open source database chosen for the implementation is Faces94 created by University of Essex. The images in this database were captured from the same distance while the subject was speaking, so they represent various, but not extreme (like in the other Essex Database called Grimace), face expressions. Moreover, the image format is supported by most of face recognition services and the size is considered as near to optimal. Unfortunately, the images were taken in a single session, so there is no variation in such details as make up, accessories or hairstyle, which is very likely to happen in real life conditions. Nevertheless, this database seems to be the best choice for our prototype.
First, local and cloud databases are populated with 34 different faces from the University of Essex Face database. Afterwards, a random face is chosen, which can belong to either one of these 34 registered people or to one of other 12 unknown people from the same Essex Database. Then the chosen face is sent for evaluation to all five face recognition services. Candidates from the returned arrays are matched against the local database and the recognition results are merged together for every unique visitor id. These data is then written to a file, which accumulates the results of 100 test runs.
The number of positive or negative results will depend on the set confidence threshold used to either accept the candidate as “recognised” or to reject him. Therefore the recognition services are called with a threshold set to 0.0, so as to get the confidence rates for all the candidates and test the collected results against every possible threshold rate. Assuming, recognisedId is the visitor id returned by the face recognition service and trueId stands for the real visitor id, all possible outcomes can be described as follows:
if (result.confidence >= threshold) AND (recognisedId == trueId) => return TPif (result.confidence >= threshold) AND (recognisedId != trueId) => return FPif (result.confidence < threshold) AND (recognisedId != trueId) => return TNif (result.confidence < threshold) AND (recognisedId == trueId) => return FN
I ran a Python script based on these rules for various confidence threshold levels to compare the performance of all face recognition services. However, there were some obstacles that made evaluations not as precise and complete as desired.
First of all, the restriction on the number of candidates returned. It differs in all services, but the most disappointing is Face++, which is only five candidates maximum. Therefore, to make comparison valid, it would be necessary to set the same maximum number of returned candidates for every other service. This, however, limits the conclusions that can be made about the results and the performance of the services. For example, setting a higher threshold will protect us from losing true positives. But at the same time, this will increase the rejection rate and slight changes in appearance may produce FN, when the user will be prompted with annoying “I could not recognise you…” list of possible candidates.
Another consideration to be made is normalization of results. From raw data received from face recognition services, it becomes obvious, that all services have different approach to setting confidence levels. The confidence level returned for the same negative person can differ from 5% to 50%. Therefore it is necessary to normalize the data before comparing different services with each other. To do this, all the results are grouped by providers and confidence values are normalised using the following formula:
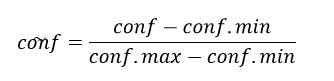
Results
Running simulations in Python for different normalized confidence threshold levels within the range from 0% to 100% with the step of 5%, has led to following results.
Response times
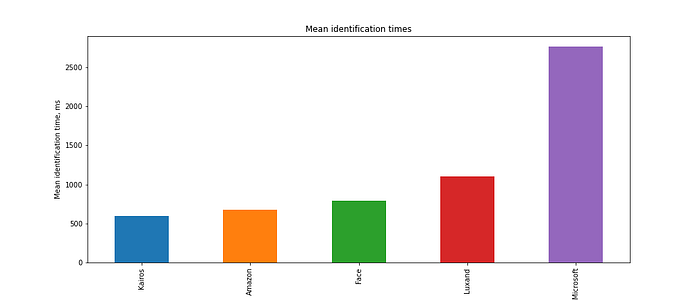
The fastest face recognition service turned out to be Kairos, which only needs 598.19 ms on average. It is closely followed by Amazon with 677.63 ms. The Chinese service provider Face++ comes third with 794.77 ms. The most surprising result was shown by Microsoft, which requires 2764.01 ms, which is almost five times longer than Kairos’ response time! This slowness may have something to do with more intricate logic and elaborate design that the API provides. It can be seen that both services that have the person feature, namely Luxand and Microsoft, came last in the response time competition. However, unlike other services, they do not just return an array of faces, but attribute every face to a unique person, which is more useful in many use cases.
Confidence sensitivity
As we discussed before, each service treats confidence levels differently, which becomes more clear from the following charts.
Apparently, there are “self-assured” and less “self-assured” services. Whereas Amazon and Luxand are almost 100% sure if they say they recognized a person, Microsoft and Kairos can be 75%-100% sure. Face++ is more like the first two and attributes to all recognized people confidence higher than 90%.
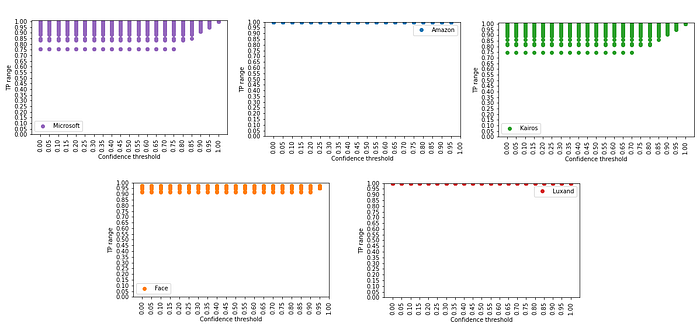
Similar conclusions can be made about confidence levels, which services attribute to their true negative candidates. It is obvious, that Microsoft, Amazon and Kairos tend to play safe and attribute to their true negatives lower confidence levels under 65%. In comparison, the starting confidence level for Face++ true negatives is around 25% and goes up to 80%. It means setting confidence threshold less than 80% can produce false negatives with Face++, whereas for Microsoft, Amazon and Kairos this threshold is around 65%. Luxand shows very unsatisfying results in these terms and seems to not distinguish faces very well, because sometimes it thinks it could recognise an unknown or wrong person with confidences close to 100%.
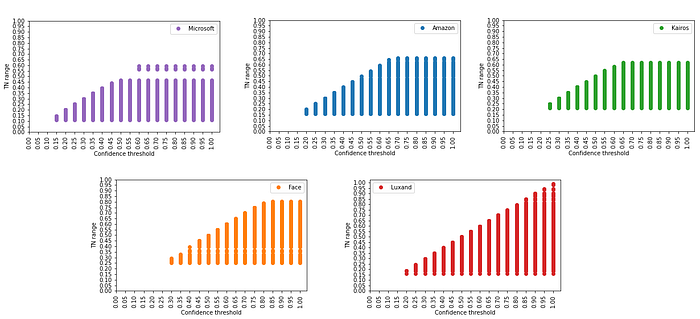
For this reason it was crucial to use normalised confidence levels, so that services can be compared in terms of TNR, Recall, Precision and Accuracy.
True Negative Rate
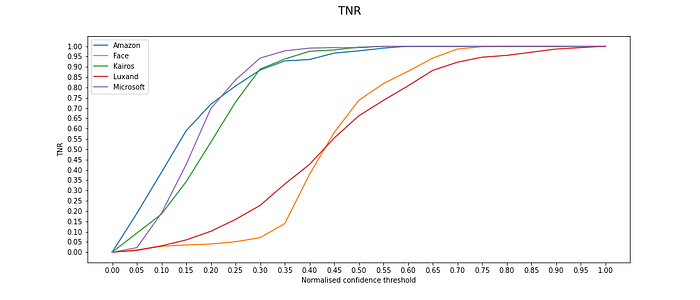
From the TNR chart it can be seen that that Amazon, Kairos and Microsoft behave very similarly and, as expected from a good face recognition service, reject people with low confidence results. On the contrary, Face++ shows confidence levels biased upwards. Luxand reacts to threshold changes very gradually, which may signify that the service does not distinguish between different faces very well.
Recall

Sensitivity, or recall, or TPR, is the extent to which actual positives are not overlooked (so false negatives are few) and measures the proportion of actual positives that are correctly identified as such. The chart shows that Kairos and Microsoft behave similarly and start rejecting true candidates early, whereas the other services tend to overlook fewer true positives. As was mentioned before, Luxand and Face++ distinguish candidates worse, which means they have more chances of mistaking one person for another, so they have less false negatives, but at the same time tend to have more false positives as well.
Precision

Precision, or positive predictive value shows is how close two or more measurements are to each other. It can be seen, that Amazon, Kairos and Microsoft distinguish between false and true visitors rather well. Face++ needs higher threshold to reach better precision. As for Luxand, the results seem to lack precision in general.
Accuracy
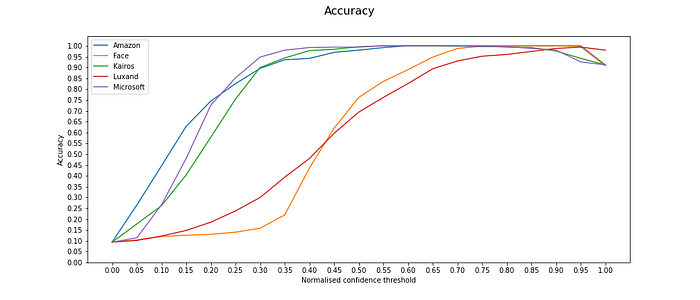
The accuracy and balanced accuracy graphs confirm previous observations: the higher the chosen confidence threshold, the more accurate are the results. However, Amazon, Kairos and Microsoft need lower threshold to show accurate results. Amazon shows very good results, both rejecting true negatives and identifying true positives. Face++ reacts to the change in confidence threshold very strongly, which has to do with the fact that the dataset only includes five possible faces, which are recognised with upwards biased confidences. As for Luxand, its accuracy changes very gradually with confidence thresholds, which can make it difficult to find an appropriate threshold, which would maximize the number of true positives and minimize false negatives.
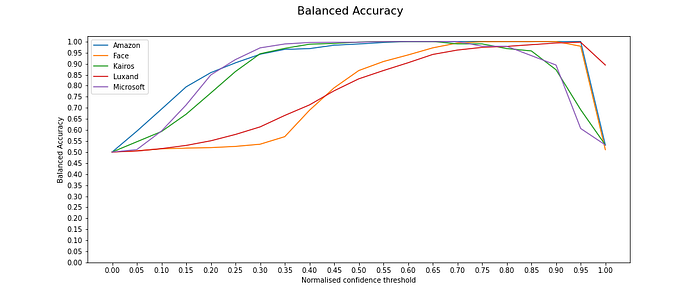
Conclusion
After this long process of evaluating five popular cloud face recognition services, we can finally pick our favourites. I would rate them in the following descending order: Amazon, Microsoft, Kairos, Face++, Luxand. It comes as no surprise, that IT giants such as Microsoft and Amazon have shown better results than smaller companies. However, Kairos also performed quite well, and the relatively poor results of Face++ can be attributed to the demographic specifics of this algorithms and the chosen database.
To sum up, this experiment proved the viability of face recognition applications on mobiles devices. Not so long ago it was perceived, that although computer vision could already be extensively used to identify people, it was still far from human vision. However, the results have shown that the situation has changed and face recognition algorithms have improved a lot.
It seems to be very likely that in the nearest future these algorithms will become even better and computers will replace humans in tasks where face recognition has to be performed. In this case mobile devices will become a common platform for face recognition applications and thanks to cloud services will be able to benefit from low latency and high performance of up-to-date face recognition algorithms.
I hope this article will motivate you to use face recognition in your mobile apps, which is a great contactless alternative to traditional means of identification.










