Android CPU, Compilers, D8 & R8
Imagine you have an important space mission ahead. You need a spacecraft that won’t get you into much trouble on the way. You may opt in a regular YT-1300 freighter. It’s popular and you know the basics of its operation. However, you’ve always dreamed of maneuvering like a pro. You are ready to practice a lot and learn various stuff. Millenium Falcon is what you actually want. But this upgraded spaceship will require that you master it like Han Solo!
Lately, I’ve been inspired by the Google effort to improve compilers, such as the development of R8 or speeding up the Gradle builds. So I guess this is the right time to dig in and talk to you about those improvements. But first, let me guide you through the basics.
When you reach the end of this article:
- You’ll know about JVM and its relation to Android.
- You’ll be able to read Bytecode.
- You’ll get an idea of the Android Build System.
- You’ll learn what AOT and JIT stand for and how they are connected to the new R8 compiler.
- And also a little bit about Star Wars :)
So grab a large cup of good coffee, the lightsaber, cookies, and prepare for a read :)
CPU & JVM
In every device, there is a CPU. It’s a tiny thing responsible for every single calculation in your app.

In the beginning, the CPU could tackle only with basic math operations such as addition, subtraction, division, and multiplication. Over the years it has evolved into a complex mechanism that can be tailored for specific needs like Image Processing, Audio Decoding with a smart caching mechanism. The most known CPU is Snapdragon by Qualcomm.

But there are others. Some of them use the same CPU architecture as Qualcomm, while some don’t. And here I say ‘Welcome to hell.’ If you’ve ever developed C++/C, you know that your native code should be compiled to every supported CPU architecture: ARM, Arm64, x86, x64, MIPS.
As an Android developer, you have to support CPU architectures for all the variety of devices. Basically, this means multiplying your .so files by the number of CPU architectures. No fun. Don’t worry I won’t go on grumbling that C++ development is not a joy.
And here the JVM comes to the rescue. The JVM (Java Virtual Machine) gives you abstraction over hardware that you’re running. This means that your app can work with a CPU via Java API and you don’t have to bother about compiling your code specifically for various CPU architectures or deal with specific Bluetooth drivers for Mac.
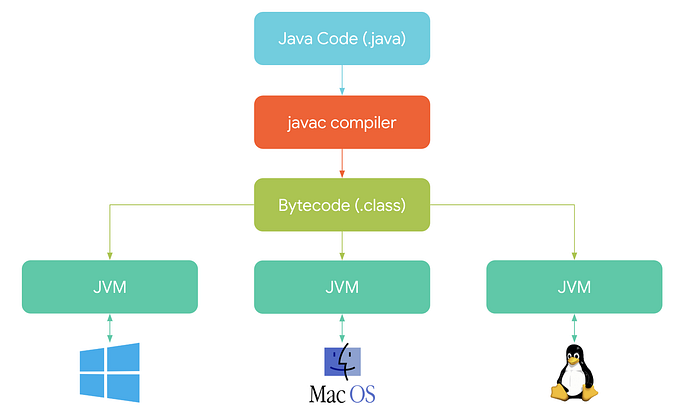
Your java code is compiled by the javac compiler into something called Bytecode (a .class file). Then your app is executed on the JVM independently of the OS. As a developer, you don’t have to think of the device types, OS, memory, or CPU. All that you care about is your business logic and making your users happy :)
Inside JVM
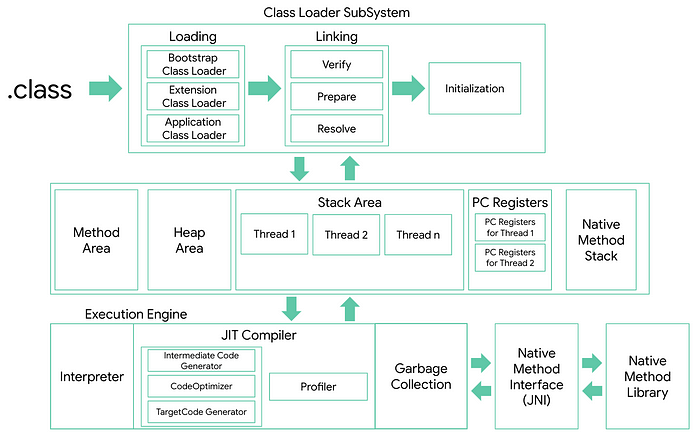
The JVM operates in three areas:
ClassLoader — responsible for loading compiled java files (.class), verifying linking, detecting corrupted bytecode, allocating and initializing static variables and static code.
Runtime Data — responsible for all program data: Stack, Method variables, and of course our loveable Heap lives here.
Execution Engine — the area for executing our compiled and loaded code and cleaning up all the garbage that we’ve generated (Garbage Collector).
At this point, you have a spaceship that can lift you, yay! But it won’t get you far. So let’s continue digging in and observing our upgrade options. I think you’re ready to learn about the Interpreter and JIT Compiler that are parts of the Execution Engine.
Interpreter & JIT
These two folks work side by side. Every time we run our program, the interpreter picks the bytecode and interprets it into the machine code. The disadvantage of the interpreter is that when one method is called multiple times, every time a new interpretation is required. Just imagine that every time an Imperial soldier is cloned you have to teach each instance to fight, hold a weapon, and conquer planets from scratch — What a waste of time!
And here comes the JIT compiler to neutralize the cons of the interpreter. The Execution Engine converts the bytecode with the help of the Interpreter, but when it finds repeated code it uses the JIT compiler, which compiles as much bytecode as it can (up to the threshold) and changes it to the native code. This native code will be used directly for repeated method calls thus improving the performance of the system. The repeated code is also called the “Hot code”.

How all of this is connected to Android?

The JVM has been designed for modern devices with endless power (as much as there is electricity in the socket) and almost unlimited storage.
Android devices are different. The battery capacity has limits, and processes compete for the resources. The amount of RAM is small, the device’s storage is usually pitiful. Therefore, when Google adopted the JVM concept, they changed a lot — Java to bytecode compilation and the bytecode structure among other things. The following code illustrates these changes:
public int method(int i1, int i2) {
int i3 = i1 * i2;
return i3 * 2;
}When this java code is compiled into the bytecode with a regular javac compiler, it looks like this:

But if we compile it with the Android compiler called Dex compiler, it changes to this:

The thing is that a regular Java bytecode is stack based (all variables are stored in a stack), while the dex bytecode is register based (all variables are stored in registers). The dex approach is much more efficient and requires less space than a regular Java bytecode. Then this dex bytecode is executed on Android JVM called Dalvik.

It loads the Bytecode compiled by Dex compiler and executes in a very similar way to regular JVM using JIT & Interpreter.
Have you noticed that your spaceship can already travel through the space vacuum? It’s upgrading fast, so you need to improve your skills to control it. Make sure you haven’t run out of cookies yet. Your brain may need some sugar now :)
Bytecode?

Bytecode is a java code compiled into the code that the JVM can understand. Reading it is actually very easy. Just look here:
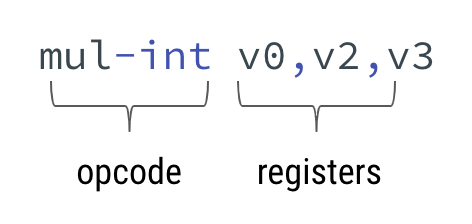
Each operation in a bytecode comprises of an opcode and registers or consonants. You may refer to the full list of all opcodes supported by Android.
All types are the same as in Java:
● I — int
● J — long
● Z — boolean
● D — double
● F — float
● S — short
● C — char
● V — void (when return value)
Classes showed with full path:
Ljava/lang/Object;Arrays start with [ and then with type:
[I, [Ljava/lang/Object;, [[IWhen you have multiple parameters in methods, it presented just as a concatenation of types.
Let’s practice:
obtainStyledAttributes(Landroid/util/AttributeSet;[III)where obtainStyledAttributes a method name, and Landroid/util/AttributeSet; — the AttributeSet class as the first parameter
[I — an array of Integers
I — Integer two times
What we’ve got at the end:
obtainStyledAttributes(AttributeSet set, int[] attrs, int defStyleAttr, int defStyleRes)
Yaay! Now you know the basics, let’s move forward:

.method swap([II)V ;swap(int[] array, int i)
.registers 6
aget v0, p1, p2 ; v0=p1[p2]
add-int/lit8 v1, p2, 0x1 ; v1=p2+1
aget v2, p1, v1 ; v2=p1[v1]
aput v2, p1, p2 ; p1[p2]=v2
aput v0, p1, v1 ; p1[v1]=v0return-void
.end method
and the same in Java:
void swap(int array[], int i) {
int temp = array[i];
array[i] = array[i+1];
array[i+1] = temp;
}But wait. Where is the 6th one?
When a method is part of an instance, it has a default parameter meaning ‘this’ which is always stored in the register — p0. And yes, you’re right. If a method is static, the p0 parameter will have a different meaning (not ‘this’).
Take a look at another example:
const/16 v0, 0x8 ;int[] size 8
new-array v0, v0, [I ;v0 = new int[]
fill-array-data v0, :array_12 ;fill datanop
:array_12
.array-data 4
0x4
0x7
0x1
0x8
0xa
0x2
0x1
0x5
.end array-data
The Java source is:
int array[] = {
4, 7, 1, 8, 10, 2, 1, 5
};And the last one:
new-instance p1, Lcom/android/academy/DexExample;
;p1 = new DexExample();invoke-direct {p1}, Lcom/android/academy/DexExample;-><init>()V
;calling to constructor: public DexExample(){ ... }const/4 v1, 0x5 ;v1=5invoke-virtual {p1, v0, v1}, Lcom/android/academy/DexExample;->swap([II)V . ;p1.swap(v0,v1)
And the java again:
DexExample dex = new DexExample();
dex.swap(array,5);Now you’ve got the super-power of reading the bytecode. Congratulations!
To move forward in our story towards D8 & R8, we need to get back to our Android JVM — Dalvik. Like in order to fully enjoy Episode I, we need to watch Episode IV first :)
Android build process
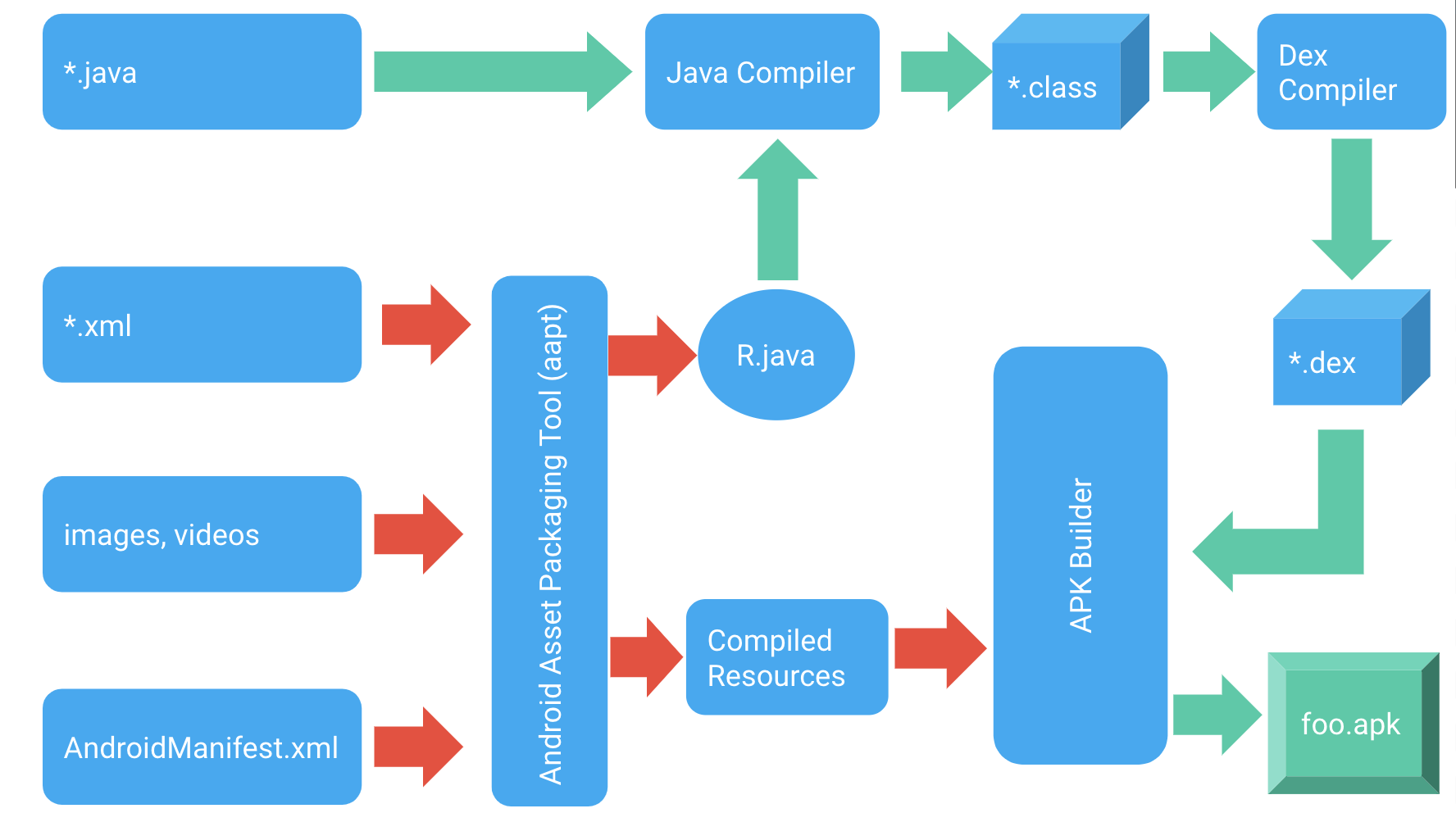
Our .java & .kt files are compiled by the Java/Kotlin compiler into .class files. These .class files are compiled into .dex by the dex compiler and finally packaged in an .apk file.
When you get an app from the Play store, you download an .apk file with all the resources (images, icons, layouts) and compiled Java code .dex and install the app on your device. By tapping on the app icon, you start a new Dalvik process — .dex code is loaded and interpreted by the Interpreter or compiled by JIT in run time — and finally you see the app screen on your device.

Enjoy your travel in a light freighter! Oh stop, you wanted an upgraded spaceship for a pro pilot. Continue upgrading your spaceship then.
ART
Dalvik was a great solution, however, it had its limitations. So Google introduced an improved JVM called ART. The main difference was that ART wasn’t running Interpreter/JIT on run time. It executed the precompiled code from an .oat binary instead resulting in much better and faster runtime. To compile code into an .oat binary, ART used the AOT Compiler (AOT stands for ‘Ahead of Time’).
What is an .oat binary?
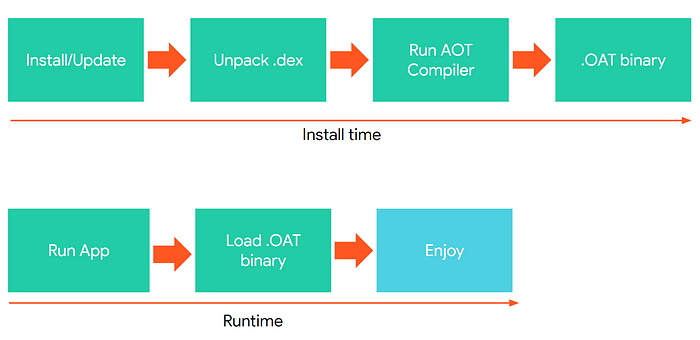
When you installed an app from the Play store, besides the .apk file unpacking, the process of compiling a .dex file into an .oat binary started.
And when you clicked on the app icon, ART loaded the .oat binary and executed it at once without any interpretation or JIT compilation.
Sounds good. But it seems that our spaceship upgrading doesn’t go so well:
- Compiling a .dex file into an .oat binary was part of the installation process, and it significantly affected the time it took to install or upgrade an app. Besides, every Android OS update launched a 1- or 2-hour “Optimizing app” process. It was a huge pain especially for Nexus owners who got monthly security updates.
- Storage space: the entire .dex file was compiled into an .oat. Even parts that were rarely used or not used at all by a user (for example, the app settings that a user set once and never returned to again, or the login screen). So basically, we were wasting space on the disk, which was a problem for low-end devices with limited storage.

But, as always in the Galaxy, Jedi come to the rescue. Google Engineers have come with a brilliant idea to combine the best: Interpreter, JIT, and AOT:
1. There is no any .oat binary in the beginning. When you run an app for the first time, ART executes the code using the Interpreter.
2. When HOT Code is detected, it’s compiled using the JIT Compiler.
3. The JIT-compiled code + the compilation profile are stored in the cache. Every future run will use this cache.
4. Once the device is idle (the screen is turned off or charging), the hot code is recompiled using the AOT compiler and the compilation profile.
5. When you run the app, the code in the .oat binary is executed at once with better performance. If there is no code in the .oatbinary, go to step 1.

On average it took about 8 app runs to optimize 80% of the app.
And here comes even bigger optimization — Why not share compilation profiles between similar devices? Done.
When a device is idle and connected to a Wi-Fi network, it shares the compilation profile files via Google Play Services. Later, when another user with the same device downloads the app from the Play Store, the device receives these Profiles for AOT to perform the guided compilation. As a result — users get an optimized app from the first use.

So how it’s connected to R8?

Folks from Google put so much effort into improving the run-time compilation. And it’s really awesome. But… We still live in the world of .dex with a limited number of opcodes supported by Dalvik/ART compiler. After reading everything above, you understand why it is like that (Dalvik is not JVM, and Dalvik Bytecode is different from JVM Bytecode).

New language features introduced in Java 7–8–9-you_name_it didn’t come to life in Android. Basically, up until recently, Android developers had to live with Java 6 SE…
To finally deliver Java 8 features to us, Google used “Transformation” — desugaring, or turning our Java 8 features during the compilation time into something recognizable by our old Dalvik/ART Compilers. But it had a downside — longer build time.
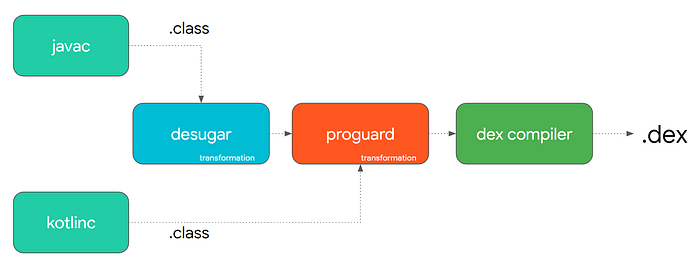
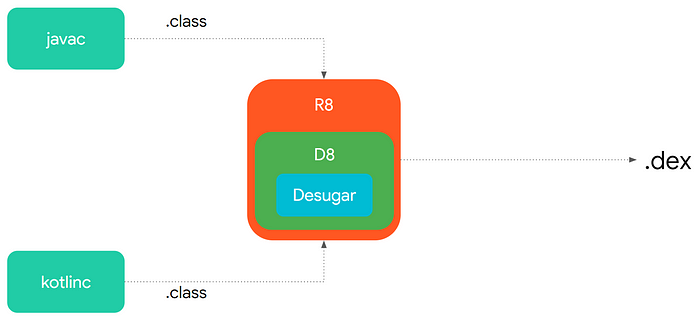
Dope8
To address this issue, in Android Studio 3.2 Google replaced the Dex compiler with a new one called D8. The main idea was to eliminate the desugaring transformation and make it part of the .class2dex compilation leading to faster build time.

How much faster? Well, it varied from project to project. With our small app, we achieved an average of 2s saved on build time in 100 builds.

Btw, there is a funny story about the name. Why D8?

But it’s not all
android.enableR8 = true (experimental AS 3.3)
R8 is a spinoff of D8. They share the same codebase. But R8 solves additional pains. Same as D8, R8 will let us use new Java 8 features on our good old Dalvik/ART. But not only this.
R8 helps to use correct opcodes
One of the biggest Android pains is fragmentation. There is a huge amount of devices running Android. Last time I checked Play Store there were more than 20k devices. *looking with envy at iOS Developers who have 2.5 devices to support* There are some devices/manufacturers that change how JIT compiler works. As a result, some devices behave in a strange way.

One of the biggest improvements R8 brings is the optimization of our .dex code by leaving only the opcodes needed to support certain devices/API level in your app. Like this one:

R8 replace Proguard?
Proguard is another transformation that is running during the build time, obviously affecting it. To solve this issue, R8 will do similar operations as Proguard does (optimization, obfuscation, removing unused classes) during the .class into .dex compilation, and not as a separate transformation.
Need to mention that R8 is not Proguard. It’s a new experimental tool that supports only a subset of the things that Proguard does. You can read more about it here
R8 is more Kotlin friendly
Developers love Kotlin. This amazing language enables us to write a more beautiful easy-to-read code. Unfortunately, the bytecode it produces contains more instructions than Java.
I took Java 8 lambda for a test:
class MathLambda {
interface NumericTest {
boolean computeTest(int n);
}
void doSomething(NumericTest numericTest) {
numericTest.computeTest(10);
}
}
private void java8ShowCase() {
MathLambda math = new MathLambda();
math.doSomething((n) -> (n % 2) == 0);
}R8 produced fewer instructions than the Dex compiler

and Kotlin lambda:
fun mathLambda() {
doSomething { n: Int -> n % 2 == 0 }
}
fun doSomething(numericTest: (Int) -> Boolean) {
numericTest(10)
}
It’s clear now that Kotlin causes more work to CPU than the good old Java. But R8 will reduce the number of instructions needed for ART to execute.
For our app, I run the build 100 times and on average, this is what I got:

13s less on build time, around 1,122 methods where removed, and smaller APK was created. Mindblowing🤯🤯🤯🤯🤯
Need to remind you that it’s experimental. And Google engineers are working very hard now to make it production-ready. Are you eager to get into this Millenium Falcon? Don’t sit it out in the rear — help us get ready for the mission.
Try it.
And submit a bug.

****
Thanks for reading. If you liked it, please give me your 👏 👏 and share this. I’ll also love to hear your comments and suggestions :) Thanks

